The Bones of High Availability
Postgres Open 2015
Postgres Open 2015

I apologize in advance.

Let's start with one node.
Just look at him...

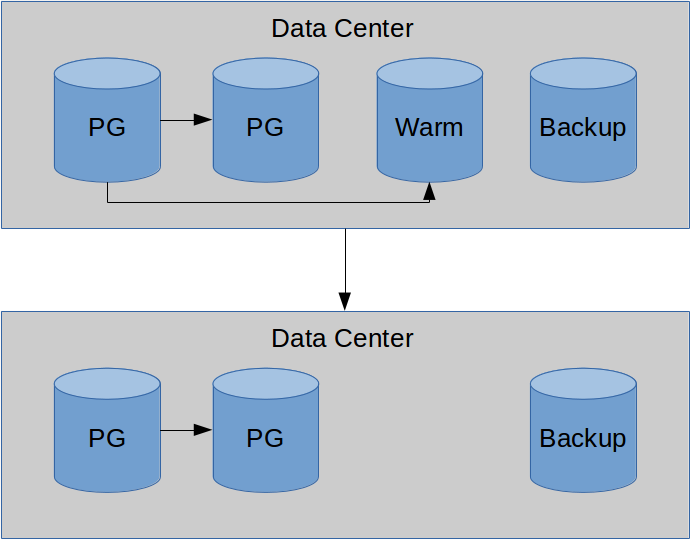
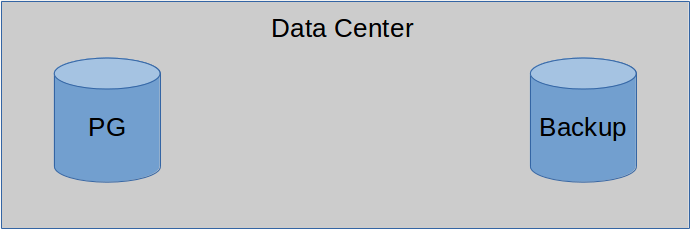
Let's move the backups and WAL archives to prevent disaster.
But backups need to be restored...
No, not that Abe!

Staying online!
Backups... are safer elsewhere.
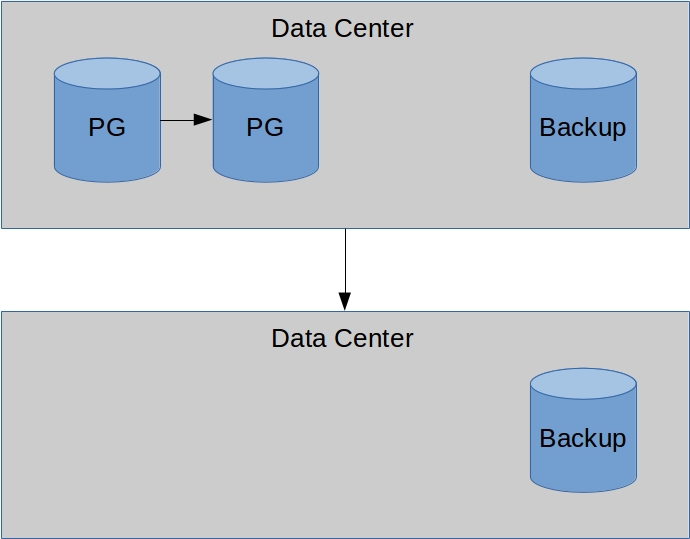
Offsite replicas are also nice.
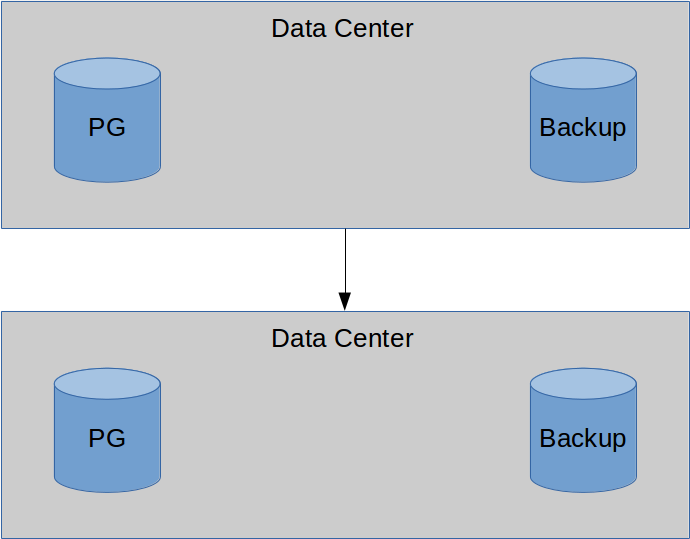
But why?
The #1 predator of The Internet!

Was your data center in Iowa?

I know my servers always run better when immersed in the Mississippi river.
To be serious for a moment, this can't be overstated. In the case of a natural disaster such as a flood, servers and data at a single location might be a total loss. If data is located externally, we can eventually bring the system up again.
Without this, a site outage may become permanent.
Remember Murphy's Law.

This really should set the tone for the rest of this talk. You can't be taken by surprise if you're always expecting something to fail.
Also, that guy is way too happy about ruining our day.
... No.

Keep Postgres running everywhere!
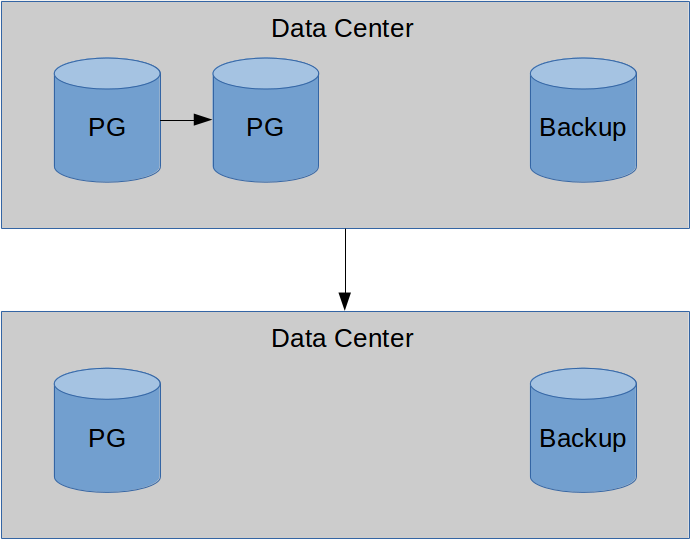
This is your foundation.
Remember this guy?
How much do we depend on our DR setup?
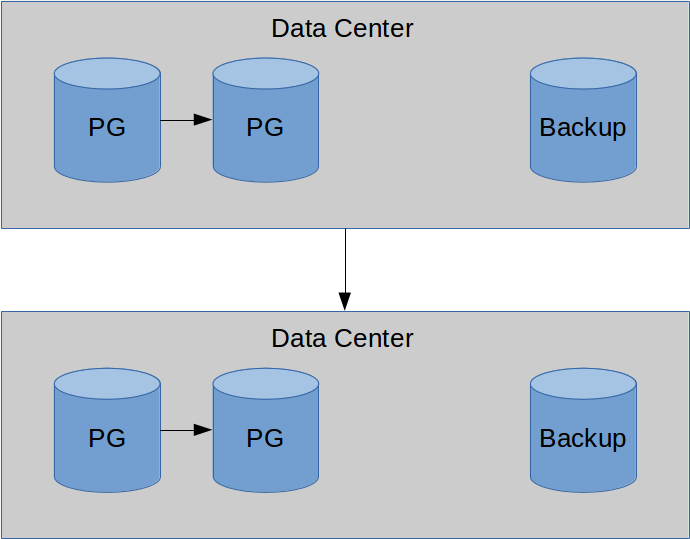
Hooray!

Hi!
I hate you!
Think about that for a second.

Have a delayed replica!