
Building Blocks and Stepping Stones
Last week I attended Postgres Conference Seattle 2024 as a speaker for two sessions. The first, titled “What’s our Vector, Victor?” discussed the merits of the pg_vectorize extension for Postgres. The second, titled “Kubernetes Killed the High Availability Star” served an advocacy piece for the ultimate deprecation of Postgres High Availability tooling in general. On day two of the event, I ended up having a long conversation about system architecture with Harry Pierson from DBOS.
That conversation caused me to miss one of the talks I planned to attend, but the experience was worth the diversion because I made a few new mental connections. Harry was saying how DBOS had a talk scheduled at KubeCon where they would explain everything Kubernetes does wrong. At one point I described Kubernetes as a “stepping stone to whatever comes next”, to which he agreed. And then I remembered stumbling across a post describing LegoOS on X.
I responded with this at the time:
It’s an interesting concept, but it requires a complete overhaul of both hardware and OS design, and still must contend with PACELC tradeoffs. You can’t defeat the speed of light.
And while I stand by that assertion, I may have been unduly dismissive of the overall approach.
A State of Transitions
When people talk about computers, they’re usually thinking of something like this:
Boring
It’s just a box with some RAM, one or more multi-core CPUs, maybe a GPU, and some storage. For the most part, that’s still what computers are. It’s what operating systems assume is going on under the hood.
Servers, with their demand for more storage than may be available to a single system, prompted the need for another paradigm: external storage. That ended up looking like this most of the time:
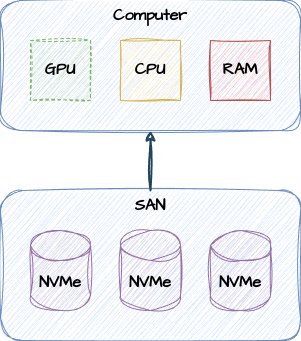
Storage Area Network
It’s still a single vertical allocation of hardware regarding compute and memory resources, but the storage is now decoupled from direct availability and becomes theoretically unlimited. This architecture allows databases to grow vastly beyond what a single server can provide, and provides a bonus transitory attribute. Did your server die? Need to upgrade? Go ahead and replace the hardware, then mount the previous storage to the new system.
Thanks to this untethering, storage systems are currently undergoing a renaissance in architecture and technology. At the one end, we have the traditional SAN, NAS, or other attached storage with dedicated communication channels. On the other, we have vastly distributed replicating CoW block storage with erasure coding for scalable redundancy across multiple regions.
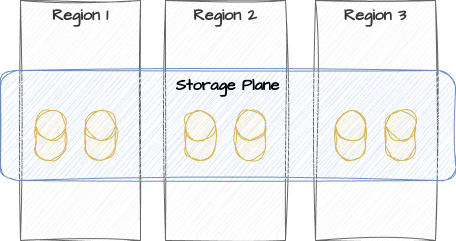
Distributed stoage with all the trimmings
As network communication speed continues to improve, these storage layers become more viable even when spread across thousands of miles. The most advanced of these filesystems will treat local writes like cache across a quorum of proximal nodes while asynchronously broadcasting across the entire fabric for long-term durability. With judiciously selected parameters, it’s possible for data to survive catastrophic failure across multiple regions.
A Virtual Companion
At some point, server hardware faced a bit of a conundrum. Servers continued to become more and more powerful within the same hardware footprint, but application stacks didn’t always require a proportional increase in resources. That led to a lot of idle servers which could otherwise be doing something else.
Enter Virtual Machines! These made it possible to slice and dice local CPU, GPU, and RAM resources for multiple concurrent workloads. Single servers transformed into something like this:
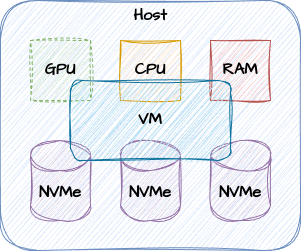
Bits and Pieces
VMs can be provided through any number of technologies, from “heavy” approaches similar to emulation, to “thin” techniques like passthrough containers. The latter is how approaches like Docker and Kubernetes function. And while the local hardware resources are shared, storage is commonly provided by some external resource.
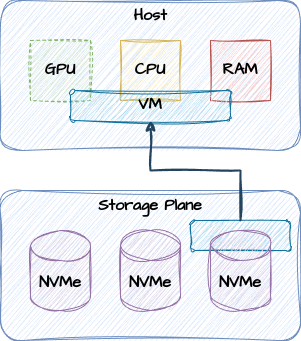
Bits and Pieces
Only now, storage is often one of those advanced distributed storage systems I mentioned earlier. It could be Amazon EBS, S3 compatible storage, something like SimplyBlock, or any from hundreds of alternatives. The VM claims some slice of storage, and the hardware couples the VM to that storage through the network. This is often within the local region, and usually within the same zone as well, but this isn’t a strict requirement. Despite this, synchronous write speeds are often as fast or faster than locally attached storage. Networks have certainly come a long way.
Despite all of this, GPU and CPU resources, commonly referred to as Compute, have strongly resisted the same decoupling we saw with storage. This should come as no surprise really, as latency is a definitive concern when it comes to strongly bonded resources like CPU and RAM.
A Planar Experience
What happens if split compute resources across nodes and regions despite the affects of latency? What happens if a VM pulls resources from arbitrary hosts?
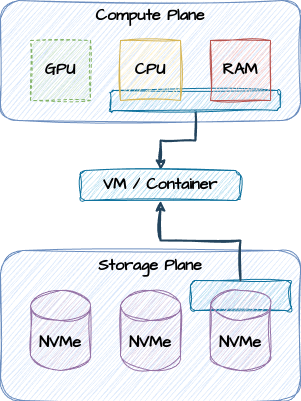
Compute slice
In the above design, the Compute plane actually looks like this:
Compute slice
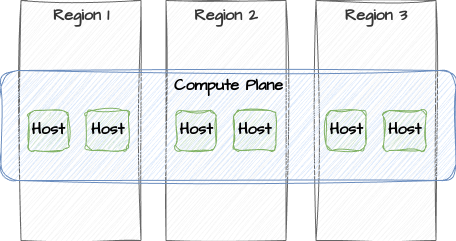
As with the storage plane, it exists as a kind of ephemeral resource provider. A VM may consist of any amount of resources within it, just as storage is currently handled in most cloud providers. This is something that isn’t currently possible because it’s an inherent limitation of most underlying operating system design.
CPUs and RAM are local resources, managed by a singular kernel. Distributed computing architectures like Kubernetes exist within the confines of this model. Users provide a declarative definition for the amount of CPUs and RAM they require, and provided a single worker node can accommodate the request, it will. But this always happens as a subdivision of a single node. If the “node” is a cloud provider, the resource is either one of their instance types (as seen with Amazon EC2, or some fragment of a node within the existing Kubernetes cluster.
It’s not possible (and may not even be preferable) for a single VM to utilize two CPUs from one node, three CPUs from another node, and two CPUs from yet a third node. As a result, every VM in existence is strictly limited to our existing CPU core and thread technology. No single VM can exist across a plurality of instances and experience infinite vertical scalability. For that to happen, we need a subsequent step toward something like LegoOS.
Putting Everything Together
It’s my opinion that Kubernetes is a single step—and a very necessary one—toward a future of resource-planes. Consider a single motherboard that provides multiple RAM, storage, and PCI slots, and can be expanded with almost infinite storage through SAS and similar techniques. In a network-driven operating-system, instead of plugging a second CPU into your motherboard, you attach a whole new host.
Except once we deconstruct the contents of a “host”, the modules themselves become infinitely variable. Compute nodes become truly nothing but a box full of CPUs paired with RAM for local memory and cache effects. Want another GPU? Click. An AI processor? Click. A box full of RAM? Click. Each “click” is the action of attaching another module to the plane, whether that be network-driven or some kind of high-end fiber connection.
Due to the distributed model, future CPU architectures will likely require larger L1, L2, and L3 caches to avoid network latency if we further decouple RAM and CPU modules. A network-aware operating system would need to prioritize local affinity to further drive down latency effects, similarly to how Linux manages NUMA. Such an operating system would likely rely on quorum similar to the Kubernetes Control Plane, but maybe not. All we’re really doing is replacing the medium of a single motherboard with a network-driven interconnect.
The major benefit of Kubernetes is that there’s not really any such thing as a “computer” anymore. All resources are split along Compute and Storage lines. More advanced database architectures like Neon Postgres even make it possible to assign multiple Compute resources to the same Storage allocation. We could extinguish every single compute resource and the database will remain. If that storage system is a distributed plane as well, we don’t even need Postgres replication anymore. Any instance in any zone in any region where the data is stored is a viable replacement compute node.
Kubernetes is essential for that kind of elastic scalability of ephemeral resources. But it’s still limited by the hardware provided by each of the worker nodes. It’s a useful API for automation and management of virtual resources, but exists within the confines of its medium. An approach like LegoOS could provide further abstraction to finally free computers from the confines of their hardware.
Eventually. We’re not ready or capable of that kind of thing yet. Perhaps we never will be, given the latency inherent to such a distributed computing model. But it works with storage, so perhaps some model is also possible for processing as well. As an abstraction layer, Kubernetes is a useful stepping stone to that end goal, provided there’s enough interest in the design.
As it stands, computers are very much a product of the design momentum of past iterations. There are standards galore for communication, integration, and abstraction, each one some advancement over a previous step. Is distributed computing such a wide departure from the existing direction that it would require unwinding several points in the stack or even starting from scratch? I’m not sure, but it’s possible.
I am curious though, what the future may bring.
Until Tomorrow