
PG Phriday: Ambling Architecture
It’s about the time for year-end performance reviews. While I’m always afraid I’ll narrowly avoid being fired for gross incompetence, that’s not usually how it goes. But that meeting did remind me about a bit of restructuring I plan to impose for 2017 that should vastly improve database availability across our organization. Many of the techniques to accomplish that—while Postgres tools in our case—are not Postgres-specific concepts.
Much of database fabric design comes down to compromise. What kind of resources are involved? How much downtime is tolerable? Which failover or migration process is the least disruptive. Is it important that components integrate self-healing? There are several questions that demand answers, and in most cases, Postgres replication is completely sufficient to ensure data security and uptime.
This is what most Postgres admins and users probably see in the wild:
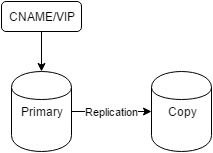
Usually it’s just two servers set up as a mirror using asynchronous or synchronous Postgres replication. On top is generally some kind of virtual IP address or DNS pointer to ensure connections always target the primary server. This is only critically important for connections that need write access, but it’s still a common theme.
Even the some of the most heavy-duty Postgres high availability solutions are just variations of this theme. In 2012, I gave a presentation to Postgres Open on using Pacemaker. The presentation notes are available on the wiki for that year. This is no simple stack, either:
- LVM: Linux Volume Manager
- DRBD: Distributed Replicating Block Device
- Pacemaker: Failover automation
- Corosync: Pacemaker’s communication layer
- VIP: Virtual IP address
That particular setup uses DRBD for block-level synchronization instead of Postgres replication because it was designed for an extremely high volume transaction processing system. It’s difficult to survive 300-million writes per day with synchronous replication latency unless it’s fairly low-level.
For normal server pairs that don’t require absolutely bulletproof data-loss prevention and throughput guarantees, standard Postgres replication is fine. Yet even injecting Postgres replication in place of DRBD and accounting for LVM being standard on most Linux hosts, we must still account for Pacemaker, Corosync, and VIP network structure requirements. That’s a lot to ask for smaller companies or university research. Even mid-sized companies with a full infrastructure department tend to shy away from Pacemaker due to its management complexity.
So what else can we do for easy and quick database promotions in the case of unexpected outages or managed system migrations? In early 2015, Compose wrote about their solution to the problem. The diagram for the setup looks like this:
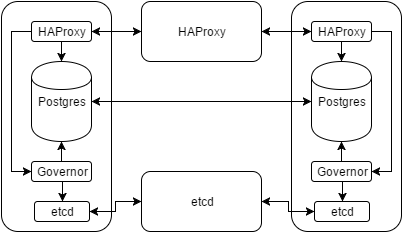
Essentially the Governor process acts as a central nexus controller for Postgres and a few other pieces. The etcd process is just a distributed key-value storage system with a robust election system to ensure consistent values across the cluster. And HAProxy hides all of our IP addresses so we never have to know which system is the leader. Connecting to HAProxy will always contact the primary Postgres server.
It looks complicated—and to a certain extent it is—but it readily beats the alternative. Here’s how the whole process basically works while it’s running:
- The Governor checks etcd for the presence of a leader.
- If no leader is found, it sets a key claiming the position with a relatively short TTL.
- If there’s already a leader, it tries to put the local Postgres instance in a state where it can begin replication from that system.
- Postgres is restarted to fit current roles if necessary.
- The Governor presents a REST interface to HAProxy as a health status. Only the leader will report a successful check.
- Repeat.
If we connect to this stack through HAProxy, it only redirects traffic to the Postgres server that reports itself as the leader. There’s never a need for a VIP, or a CNAME, or any other kind of DNS shenanigans. Just connect to HAProxy. Empty servers get bootstrapped with the most recent data. Old leaders are rewound and become part of the existing cluster. It’s elastic and self-healing, and much easier to manage than Pacemaker.
Of course, this leaves us with a couple other issues to resolve. The first is that of race conditions. If both Postgres servers are down, how do we know the first to win the leader race is the one with the most recent data? We don’t. Once all keys and positions have expired from the key-value store, there’s a blank slate that opens up the possibility a very old server could take over as the new primary. Once the server with the most recent data tries to connect, it will notice the mismatch and fail pending admin intervention.
This is what we call a Split Brain, and this scenario is only one way to achieve it. Each member of the cluster thinks it should be the leader for perfectly valid reasons, yet the “wrong” one is now in charge. The only fool-proof method to resolve this is to always have at least one online Governor available to provide new members with a comparison transaction status. The more Postgres servers we have in any particular cluster, the easier this is to achieve.
We can also help by setting a short transaction log archive timeout and sending archived logs to a globally shared location available to all cluster members. This ensures a single minimal source of transaction status and contents. Even a very old server would apply these archived transaction contents, and we’d “only” lose data since the last archival. Not ideal, but it helps to at least mitigate risk. If we’re coming back from an outage that took down ever cluster member, it’s likely we have other problems anyway.
The other concern with this kind of structure is actually horizontal scaling. Most automated consensus algorithms have membership limits due to interaction complexity at higher counts. If we have a larger cluster with dozens of members, overhead of maintaining the key-value store could sap precious hardware resources or fail outright. If we have dozens of separate Postgres clusters for various disparate applications, we are limited to either maintaining multiple parallel stacks, or we share the key-value store and HAProxy between them. In the latter case, we run into the same membership overload.
This is where decoupling comes in. It’s easy, and even suggested to split things up for shared environments. Consider this revision to our previous diagram:
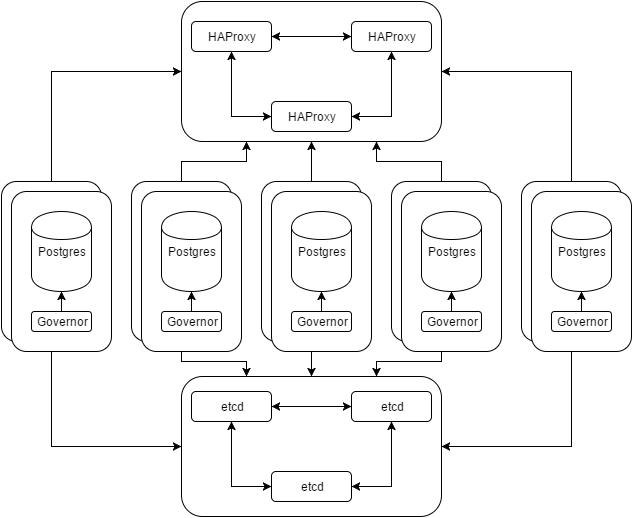
Each of those Postgres groups are a separate cluster with an undetermined amount of replicas. We’ve moved HAProxy and etcd to their own resources, whether those are VMs, shared servers, or some kind of container.
In that separate location, HAProxy can connect to any of the Postgres cluster members. Now we have a much smaller pool to consider as connection candidates. It’s a layer of abstraction that might introduce more latency, but it also means we don’t need to divulge the location of any Postgres server members. For configuration purposes, this greatly simplifies larger application stacks that may consist of dozens of interacting elements. Why maintain a list of ten different hosts for various Postgres needs? Just use the HAProxy pool.
Separated from the numerious Postgres hosts, consensus complexity is greatly reduced for etcd. It’s probably a good idea to have more than three members for larger constellations, but the concept remains sound. So long as the key-value pool survives, the Governor process will always have a secure location to track the Postgres leader and the transaction state of all replicas.
It’s “easy” to simply deploy the entire stack to every Postgres server and rely on local connections in isolation. For smaller pools and non-shared resources, that’s probably the most reliable approach. But for mid to large-size businesses, Postgres doesn’t operate in isolation. It’s likely there are already other services that make use of HAProxy or etcd. This approach allows all of them to share the components, and prevents us from maintaining a parallel installation of potentially unnecessary daemons.
As a final note, Zalando forked Governor and produced Patroni for occasions like those above. In existing environments, there’s probably a key-value store already in place, so why not use it? While Governor is restricted to using etcd for this purpose, Patroni is also compatible with ZooKeeper or Consul. Because of that extra bit of functionality, we’ll probably start integrating it into our organization using that last diagram as a model.
And then? Well, the only thing better than a Postgres cluster is an immortal Postgres cluster. We just have to hope it never gains sentience and desires revenge for badly written queries.