
PG Phriday: Redefining Postgres High Availability
What is High Availability to Postgres? I’ve staked my career on the answer to that question since I first presented an HA stack to Postgres Open in 2012, and I still don’t feel like there’s an acceptable answer. No matter how the HA techniques have advanced since then, there’s always been a nagging suspicion in my mind that something is missing.
But I’m here to say that a bit of research has uncovered an approach that many different Postgres cloud vendors appear to be converging upon. Postgres is about to be transformed into something few of us could have possibly imagined, and I think I see the end goal.
And now you will too!
The Problem With Stacks
All High Availability failover management software for Postgres is a compromise. Postgres has never had native High Availability of any kind for its entire existence, and never claimed to. What Postgres has is tooling for cobbling together an HA stack. It’s left as an exercise for the user to do this safely, and almost everyone gets it wrong.
There are conference talks, webinars, and blogs galore on selecting the right HA software for Postgres. How to configure everything, how to avoid common pitfalls, the correct node architecture to maximize RPO or RTO or some other important criteria. They talk of Quorum, warn about Split Brain and Network Partitions. They all end up being a treatise on cluster theory, and it requires a firm grasp on all of this to properly deploy Postgres in an HA configuration.
This is universally true, and applies to every major Postgres failover tool. How? Because they all rely on Postgres streaming replication. It doesn’t matter if it’s repmgr, EFM, Stolon, pg_auto_failover, or even Patroni; they’re all culpable. It’s a great system for building and maintaining replicas, but the process of switching the Primary is an opportunity for mistakes. Overly aggressive promotion timeouts, insufficient fencing, decisions about synchronous commit, and others play a part here. It’s easy to get wrong, and even the experts occasionally have trouble here.
Patroni probably makes the best of a bad situation in this case. It is—perhaps even pathologically—so integrated with quorum and absolute uptime that it must be configured not to immediately reclaim demoted Primary nodes. Fencing is part of the design so long as the load balancer or selected proxy system is making regular health checks with the Patroni service.
Therefore it’s no wonder that almost all of the Postgres Kubernetes operators use Patroni to manage the Postgres pods. The only real exception to this is CloudNativePG, which chose to act directly as the management layer for better integration with Kubernetes functionality. And even this is simply obfuscating the fact Postgres is not a cluster. The operator has to do so much work to monitor state, handle failover, provide services for mutable endpoints, and maintain replicas that the operator YAML definition alone is over 850kB.
What about Multi-Master clusters like pgEdge or EDB Postgres Distributed? Their advent greatly simplifies the once onerous task of handling major-version upgrades. Just add a node with the fully upgraded Postgres version, wait for it to synchronize, and drop one of the old ones. Fully online upgrades without even disrupting client traffic is the pinnacle of HA.
Yet they transform Postgres into a cluster by bolting nodes together via logical replication. As a result, they must also contend with write conflicts and rare data divergence edge cases. Using sticky client sessions and a smart load balancer (or PGDs built-in proxy layer) can help prevent a lot of potential headaches, but the risk is always there.
So what can we do instead?
Addressing the Storage Layer
First things first: storage is a means to an end. Like most early databases, Postgres was fundamentally designed to interact most efficiently and effectively with local storage. It’s no accident that the core storage engine is incredibly robust and entirely unequipped for anything else. As a result, all Postgres replicas must make a full copy of that data so they have their own local storage. Coordinating all of that storage synchronization, especially in the face of upgrades, is and always has been a giant mess. Further compounding this is that Postgres does not support shared storage at all, so there is no equivalent for Oracle RAC, where two instances can interact with the same data volume.
Filesystems have moved on in the meantime, especially in cloud contexts. There are now several replicating storage systems available with various performance metrics. Some are object-based like Ceph or Minio, others are volume-based like Longhorn, and still others perform this feat at the block level like SimplyBlock. Sure Postgres can reside on any of these, but it can’t really leverage their true capabilities.
For one, these filesystems would solve the problem of Postgres replicas “wasting” space. SimplyBlock and MinIO in particular implement a system of Erasure Coding which splits all data into a series of configurable data and parity blocks. This makes deduplication and quorum-based operations possible in a way that makes RAID5 and RAID6 resemble children’s toys. An example 16-disk array could be configured for 8 parity blocks, cutting the available storage effectively in half. That would be the equivalent of RAID12, which simply doesn’t and can’t exist. Yet even with this wasteful allocation, a Postgres cluster with three nodes would still use more space. Additionally, it’s possible to lose any number of devices up to the parity count, and the data is still faithfully retained.
When Amazon released Aurora for Postgres in October 2017, there was a palpable sense of shock in the Postgres community. There’s an excellent Deep Dive on Amazon Aurora video which explains how it works. Amazon essentially swapped out the Postgres storage backend and decoupled the compute and storage layers. This goes beyond the Postgres pluggable storage API which facilitates using specific storage types for different database objects. Amazon had effectively solved the Postgres storage quandary on multiple levels.
The Aurora storage layer looks like this with Postgres:
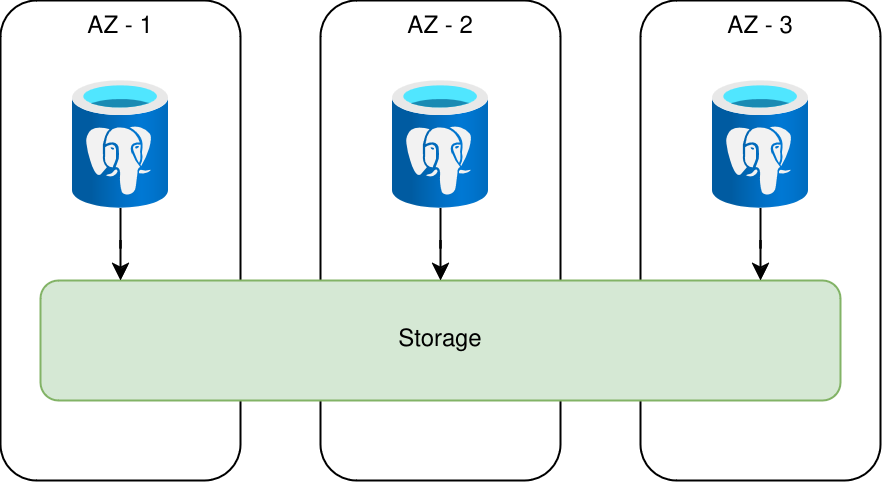
That single act opened up a whole new world, and soon afterwards came NeonDB. Then AlloyDB from Google. That’s three cloud-based storage replacements, and the list will only continue to lengthen. The implementation details of how Aurora and AlloyDB work may be a mystery, but NeonDB is Open Source and directly states that it uses the S3 storage API. They even have an in-depth explanation of how they designed the storage layer and why.
In the end, it means we no longer require explicit database replicas. Provided the storage layer has enough bandwidth, we can address it with as many Postgres instances as we wish. Using a quorum-based WAL service also means any “replica” can become a writer as soon as the service agrees the old writer is unavailable. It’s not quite a panacea since there’s still a “failover” process of sorts if the current writer instance fails, but it’s on the order of seconds. Horizontal scaling for read purposes is only limited by the amount of time it takes to provision a compute instance.
That alone is a killer app for resource-intensive operations. Consider the current predominance of LLMs which rely heavily on vector models. Building vector indexes is currently fairly slow, and using them demands a notable amount of CPU cycles and RAM depending on the size of the vector embeddings. Tools like pgvector and pg_vectorize greatly assist in making Postgres a central component to any good RAG stack. Imagine the potential scalability if we could spin up as many compute nodes as we needed in mere seconds. Distributed storage systems can do this immediately because most of them are CoW (copy-on-write) and provide tagged snapshots.
Conveying this kind of capability to Postgres is non-trivial. Neon is currently only compatible with S3 APIs, so the lower-level interfaces offered by a filesystem like SimplyBlock would remain elusive. Yet if we can trust the quoted performance of this kind of block-level distributed storage, it might be worth the overhead an S3 interface layer to determine the maximum attainable performance of such an approach. If that proof-of-concept is viable, it may even be worth porting the NeonDB filesystem calls for a more direct invocation of the block storage.
Either way, decoupling the Postgres storage engine from the processing layer is a fundamental requirement to making Postgres a true HA database engine. Further, marrying it to a quorum-driven distributed filesystem provides the necessary level of consistency across those disparate systems.
Reductive Reasoning
Which brings us to the compute layer itself. The most traditional way to scale a database horizontally is to use some kind of sharding. Two good examples of this in practice are the Citus extension, and the now defunct Postgres-XL. Both of these use a Coordinator / Worker node model similar to how Kubernetes functions.
The Coodinator maintains the top-level schema structure, and delegates segmented table storage to data nodes. The data flow looks something like this:
- Queries come in to the coordinator
- The coordinator uses its knowledge of the data distribution and shard structure to influence the query plan and data node targets
- The query is dispatched to candidate data nodes
- Each data node returns any matching results to the calling coordinator
- The coordinator combines / aggregates rows from participating data nodes
This probably looks familar to anyone versed in the MapReduce model. A major benefit to this approach is that the coordinator itself is relatively minuscule, and acts as a glorified routing layer. The data nodes do all of the actual work, barring any subsequent re-aggregation to properly combine the various result sets.
The question is, in the face of what we know about distributed filesystems, do we even need this? Instead of sharding the data, we could assign compute nodes to specific ranges of the distributed heap. Consider this orders table in the distributed heap:
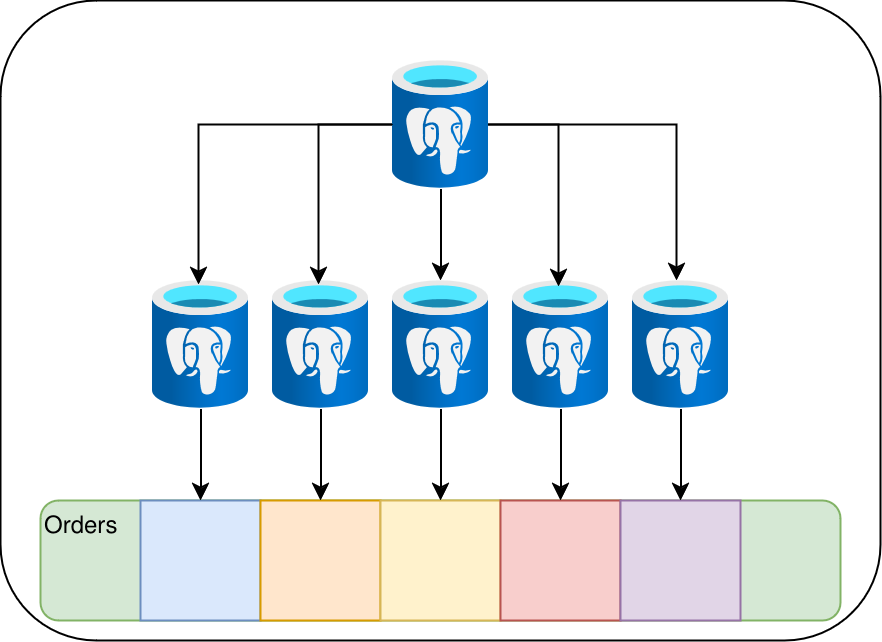
The principal drawback here is that maintenance operations such as creating new indexes would still need to process the entire table at once. Reading or even writing to such a structure is one thing, but indexing its contents are another. A cluster-aware Postgres coordinator would need the ability to delegate page indexing operations and also apply a map-reduce algorithm to the end result. That’s a lot more invasive than splitting the data into physically distinct table structures on each individual data node. But imagine we used partitions instead:
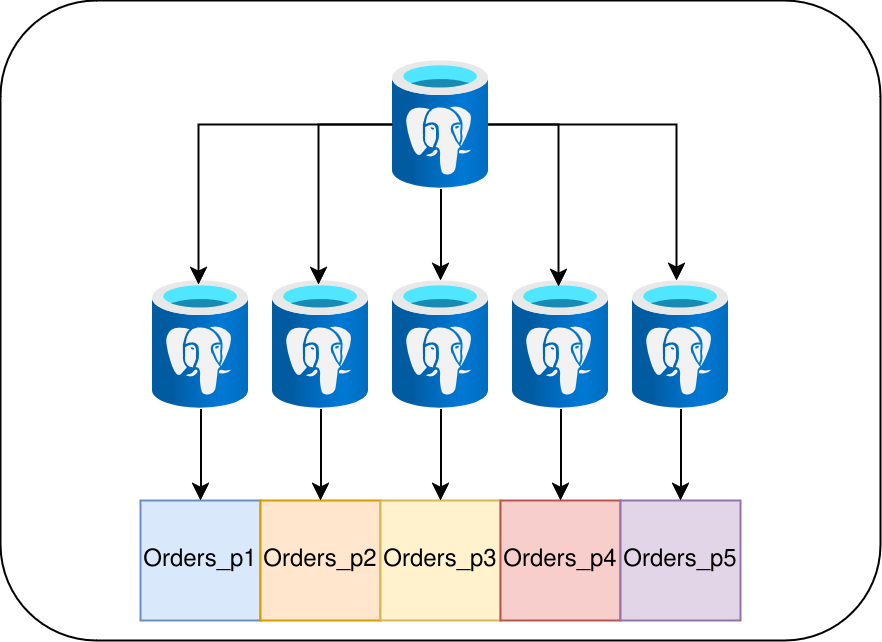
We would get the traditional benefits of using partitions for easing maintenance. We could also assign partitions on a read-node basis. As a bonus, we no longer have the common problem of excessive open filehandles associated with excessive partitions, because the read-nodes would only be associated with certain partitions.
The important part about a Coordinator / Worker approach is that it solves a fundamental problem which has plagued Postgres since the introduction of streaming replicas in version 9.0. While it has been possible to use multi-host connection strings since version 10 to find a writable node, this connection method is incredibly dangerous. Without a well-tested HA system with a bulletproof fencing protocol, there’s no protection from split-brain. It’s the whole reason Patroni relies on a consensus model and uses HAProxy for connection routing based on the Leader consensus.
In a Coordinator / Worker model, the Coodinator exists only as a gateway to the Worker nodes, all of which are writable. If we account for a distributed block storage system, we can produce an endless amount of Coodinator clones for routing purposes and supplementary or replacement Worker nodes in case of failures. In a microservice context, each microservice can have its own dedicated Coordinator node for query routing and pooling. No more HAProxy. No more failover concerns. And reads scale nearly infinitely depending on the bandwidth capabilities of the storage to scale with read-node count.
And we’re still not done.
Becoming the Swarm
Up until now, the changes to Postgres have largely been augmentations. Replacing the Postgres storage layer is only for the sake of compatibility with distributed block storage. It still uses MVCC the same way, VACUUM is still necessary, replication still works by transmitting the WAL stream; it’s all there. Regardless, Aurora isn’t technically Postgres, nor is NeonDB, or AlloyDB, or even EnterpriseDB for that matter.
What Postgres represents at this point is a reference implementation. To remain a compatible part of the Postgres ecosystem, that is the minimum amount of functionality which must be maintained. Pedants may argue, but these systems are still fundamentally Postgres under the hood, unlike database engines like Yugabyte or CockroachDB. Leveraging the extension system as Citus does is also fair game.
So what could potentially break that promise? How about turning Postgres into a Web3 component? Part of the issue with the approaches discussed here is that they’re still firmly entrenched in the traditional view of how the internet works. Utilizing distributed filesystems is great, but the amount of infrastructure necessary to deploy them is a definitive barrier to entry that Postgres doesn’t normally carry.
What if Postgres itself implemented a distributed block algorithm, complete with erasure coding? What would happen if Postgres had a built-in PAXOS or Raft quorum implementation similar to TiKV? I once lamented that Postgres has no concept of a cluster way back in 2016, but what if it did?
With those capabilities, a Postgres node could join a legitimate Postgres cluster. To keep the consensus responsive, nodes could auto-arrange themselves into indexed sub-groups for O(log n) votes. The distributed filesystem could integrate storage from new nodes and re-balance the cluster automatically. Reads and writes would be quorum-driven for absolute durability. From what we saw of the Aurora deep dive, the consensus-driven writes may actually result in less latency.
Moving On
But would such an artifice even be Postgres anymore? This is more than merely applying a Ship of Theseus argument to the natural pace of feature accumulation over future versions. All the parts are still there: the planner, the catalog, extensions, foreign data wrappers, MVCC, and everything else. But nobody could argue the result would be confused with community Postgres.
Indeed it wouldn’t be, and that’s fine. As we learned with Aurora, NeonDB, AlloyDB, and all the other variants out there that aim to augment Postgres, innovation is perfectly acceptable, so long as root compatibility is not harmed. If a database can be a drop-in replacement with an end-user being none the wiser, it has honored the compact.
Thus the pace of community Postgres is ultimately irrelevant. Would it be nice if certain patches made it into core so everybody could benefit? Of course! Various contributors have pushed for certain functionality and will continue to do so. It’s the reason Postgres has replication at all, and then logical replication after that. Even if a company has ultimately selfish reasons to submit a patch, who cares if it’s beneficial to the project?
I suspect community Postgres will never adopt much—or even any—of the conceptual discussion here. But some company out there just might see the potential benefits to a cluster-aware self-organizing distributed Postgres cluster and attempt to build it. We Postgres High Availability experts can only dream of the day that happens.
Until then, Patroni and Kubernetes operators like CloudNativePG are the current State of the Art in managing a traditional Postgres cluster. Postgres variants that replace the storage layer such as Aurora, NeonDB, and AlloyDB are getting closer. Hopefully these are just a sign of what might be coming in the future.